

SEUR dostarcza ponad 300 000 paczek dziennie flotą 4 700 pojazdów. Przy takiej skali jeden zbędny kilometr na zamówienie przestaje być detalem — staje się problemem strukturalnym.
Gdy SEUR wspólnie z CARTO sprawdził, czy jego sieć transportu chłodniczego jest optymalnie zaprojektowana, odpowiedź brzmiała: nie. Różnica między stanem obecnym a optymalnym wyniosła 380 000 kilometrów rocznie.
Oto jak do tej liczby doszli.
Istnieje pewien paradoks w logistyce. Im większa firma, tym bardziej każda pozornie drobna nieefektywność operacyjna urasta do rangi strategicznego problemu. Różnica jednego kilometra na zamówienie jest niezauważalna, gdy patrzysz na pojedynczą trasę. Staje się widoczna, gdy pomnożysz ją przez setki tysięcy zamówień rocznie.
SEUR to jedna z największych firm kurierskich w Europie, założona ponad 75 lat temu, z pozycją lidera rynku w Hiszpanii. Skala jej operacji nie pozostawia miejsca na przybliżenia: ponad 1,2 miliona klientów, ponad 300 000 paczek dostarczanych każdego dnia, flota 4 700 pojazdów. Trzy główne linie biznesowe — dostawy międzynarodowe, e-commerce i B2B — obsługiwane równolegle, w każdych warunkach pogodowych i rynkowych.
W tym kontekście SEUR zdecydował się na współpracę z CARTO w celu optymalizacji sieci transportu chłodniczego — jednego z najbardziej wymagających segmentów logistyki, gdzie każde opóźnienie lub nieoptymalna trasa niesie konsekwencje zarówno kosztowe, jak i jakościowe. Wynik tej współpracy: redukcja średniej odległości transportu z 18,99 km na zamówienie do 18,23 km na zamówienie. Dla 500 000 zamówień rocznie oznacza to 380 000 mniej przejechanych kilometrów — z bezpośrednim przełożeniem na koszty paliwa, wielkość floty i jakość obsługi klientów.
To studium przypadku pokazuje nie tylko wynik, ale przede wszystkim drogę: jak konkretnie CARTO i zespół Spatial Data Science SEUR doszli do tych liczb, jakie techniki zastosowali i dlaczego podejście iteracyjne — stopniowe zwiększanie złożoności modelu — okazało się kluczem do sukcesu.
Transport chłodniczy rządzi się surowszymi regułami niż standardowa logistyka kurierska. Produkty wymagające kontrolowanej temperatury — żywność, leki, wyroby farmaceutyczne — muszą być przewożone w ściśle określonych warunkach, z zachowaniem ciągłości łańcucha chłodniczego od momentu odbioru aż do dostarczenia do odbiorcy. Każde odchylenie od optymalnej trasy, każde przeciążenie centrum dystrybucji, każda zbędna godzina w transporcie to potencjalne ryzyko dla jakości produktu, nie tylko koszt.
Rynek cold chain globalnie rośnie w tempie znacznie przekraczającym ogólną logistykę. Rosnące zapotrzebowanie na dostawy żywności świeżej, mrożonej i produktów farmaceutycznych — wzmocnione przez boom e-grocery i e-pharmacy — sprawia, że operatorzy zimnych łańcuchów dostaw muszą nie tylko obsługiwać większe wolumeny, ale robić to coraz efektywniej kosztowo i środowiskowo.
SEUR stanął przed wyzwaniem, które jest typowe dla dojrzałych operatorów logistycznych: sieć dystrybucji, zbudowana historycznie i rozwijana organicznie przez dekady, nie była już optymalnie dopasowana do aktualnego rozkładu popytu. Centra dystrybucji (DC) były zlokalizowane na podstawie decyzji podejmowanych lata lub dekady wcześniej. Obszary dostaw poszczególnych centrów były wyznaczone według granic administracyjnych lub historycznych podziałów, niekoniecznie odzwierciedlających rzeczywistą geometrię popytu i koszt obsługi.
Pytanie, które SEUR i CARTO postawili sobie na początku współpracy, brzmiało precyzyjnie: czy obecna sieć jest zaprojektowana optymalnie? A jeśli nie — jak ją zmienić, by zmaksymalizować efektywność przy zachowaniu lub poprawie jakości obsługi?
Zanim zaczęto pisać jakikolwiek algorytm, CARTO i SEUR precyzyjnie zdefiniowali trzy hierarchiczne cele projektu. To ważny element metodologii, który odróżnia profesjonalne podejście do optymalizacji sieci od doraźnych poprawek.
Cel pierwszy: ocena stanu obecnego. Zanim można cokolwiek optymalizować, trzeba dokładnie zrozumieć punkt wyjścia. Gdzie koncentruje się popyt? Jakie są charakterystyczne cechy obszarów o wysokiej gęstości zamówień? Czy obecne centra dystrybucji są rozmieszczone strategicznie względem tego popytu? To pytania diagnostyczne, które wymagają danych historycznych i narzędzi do ich przestrzennej analizy.
Cel drugi: pomiar wpływu zmian w istniejącej sieci. Zanim podejmie się decyzję o otwarciu lub zamknięciu centrum dystrybucji, należy wiedzieć, jakie będą konsekwencje tej decyzji dla całej sieci — nie tylko dla najbliższego obszaru. Które inne centra przejmą obsługę? Jak zmieni się średni dystans transportu? Jak zmieni się obciążenie floty? Odpowiedź na te pytania wymaga modelu symulacyjnego, nie intuicji.
Cel trzeci: zbudowanie modelu optymalizacyjnego. Docelowo — stworzenie narzędzia, które nie tylko ocenia stan obecny i symuluje scenariusze, ale wskazuje, gdzie centra dystrybucji powinny być zlokalizowane i jak powinna wyglądać optymalna sieć transportowa. To najbardziej zaawansowany poziom, wymagający pełnej formalizacji matematycznej problemu.
Jakość każdej analizy przestrzennej zależy bezpośrednio od jakości i kompletności danych wejściowych. W projekcie SEUR × CARTO do modelu trafiły trzy kategorie danych.
Pierwsza to dane historyczne zamówień — zgeolocated dane o dostarczonych zamówieniach z okresu szczytowego (peak season) oraz poza sezonem (off-season), z dokładnością do adresu dostawy. Ten podział na sezon i poza-sezon był nieprzypadkowy: logistyka chłodnicza ma wyraźną sezonowość, a system musi sprawnie działać zarówno w szczytach obciążenia, jak i w spokojniejszych okresach.
Druga kategoria to dane o centrach dystrybucji — lokalizacja każdego DC oraz jego pojemność operacyjna. Ten drugi parametr okazał się kluczowy na późniejszych etapach optymalizacji, gdy model musiał uwzględniać ograniczenia przepustowości.
Trzecia kategoria to dane o terytoriach biznesowych — obecne obszary dostaw przypisane do każdego centrum dystrybucji. To właśnie te podziały miały zostać zakwestionowane i zoptymalizowane w toku projektu.
Kluczowe metryki, według których oceniano wyniki, to średnia i maksymalna odległość pokonywana przez pojazdy od DC do klientów oraz równowaga obciążenia między centrami dystrybucji w sezonie szczytowym — różnica w stopniu wykorzystania pojemności między poszczególnymi DC.
Pierwszym krokiem analitycznym było przeprowadzenie analizy klastrów przestrzennych w celu identyfikacji obszarów o wysokiej koncentracji zamówień. Cel był dwojaki: zweryfikować, czy obecne DC są zlokalizowane blisko rzeczywistych centrów popytu, oraz zidentyfikować przestrzenne charakterystyki gęstych obszarów — zasięg terytorialny, strukturę administracyjną, wzorce sezonowe.
Do tego celu CARTO zastosował algorytm DBSCAN (Density-Based Spatial Clustering of Applications with Noise) — nieparametryczny algorytm klastrowania oparty na gęstości. DBSCAN grupuje razem punkty, które są blisko siebie skupione, oznaczając jako anomalie punkty leżące w rzadko zaludnionych obszarach. Jego zaletą w kontekście logistycznym jest to, że jego dwa parametry można bezpośrednio przełożyć na kryteria biznesowe.
Pierwszym parametrem jest maksymalna odległość między próbkami — w tym przypadku maksymalny dystans między dwoma zamówieniami, przy którym jedno jest uznawane za sąsiedztwo drugiego. Drugim jest minimalna liczba próbek tworzących klaster — minimalna liczba sąsiednich zamówień, by obszar był uznany za strefę wysokiej gęstości. Oba parametry można kalibrować na podstawie wiedzy operacyjnej o specyfice rynku.
Algorytm uruchomiono wielokrotnie z różnymi wartościami parametrów i różnymi agregacjami czasowymi: dla wszystkich danych historycznych łącznie, oddzielnie dla szczytu i poza-sezonu oraz w cyklach miesięcznych. To pozwoliło na analizę zachowań przestrzenno-czasowych popytu — kluczową dla operatora cold chain, gdzie sezonowość ma silne implikacje dla planowania sieci.
Wyniki analizy klastrów ujawniły kilka charakterystycznych wzorców przestrzennych. Długie, rozciągnięte klastry wzdłuż linii brzegowej (Málaga, Alicante) odpowiadały koncentracji turystyki i przemysłu spożywczego w pasie nadmorskim. Zwarte, okrągłe klastry skupione wokół dużych miast (Madryt, Walencja) odzwierciedlały gęstość miejskich obszarów zamieszkałych. Duże obszary niskiej koncentracji zamówień wskazywały na regiony, gdzie utrzymywanie dedykowanego DC może być kosztowo nieuzasadnione — co natychmiast postawiło pytanie: czy można skonsolidować część centrów bez istotnego pogorszenia czasu dostawy?
Strategiczne i taktyczne planowanie sieci logistycznej nie wymaga precyzji co do każdego konkretnego adresu. Zamiast analizować pojedyncze zamówienia, efektywniej pracować na agregacjach przestrzennych — komórkach siatki lub jednostkach administracyjnych, które grupują pobliskie zamówienia w zarządzalne jednostki analityczne.
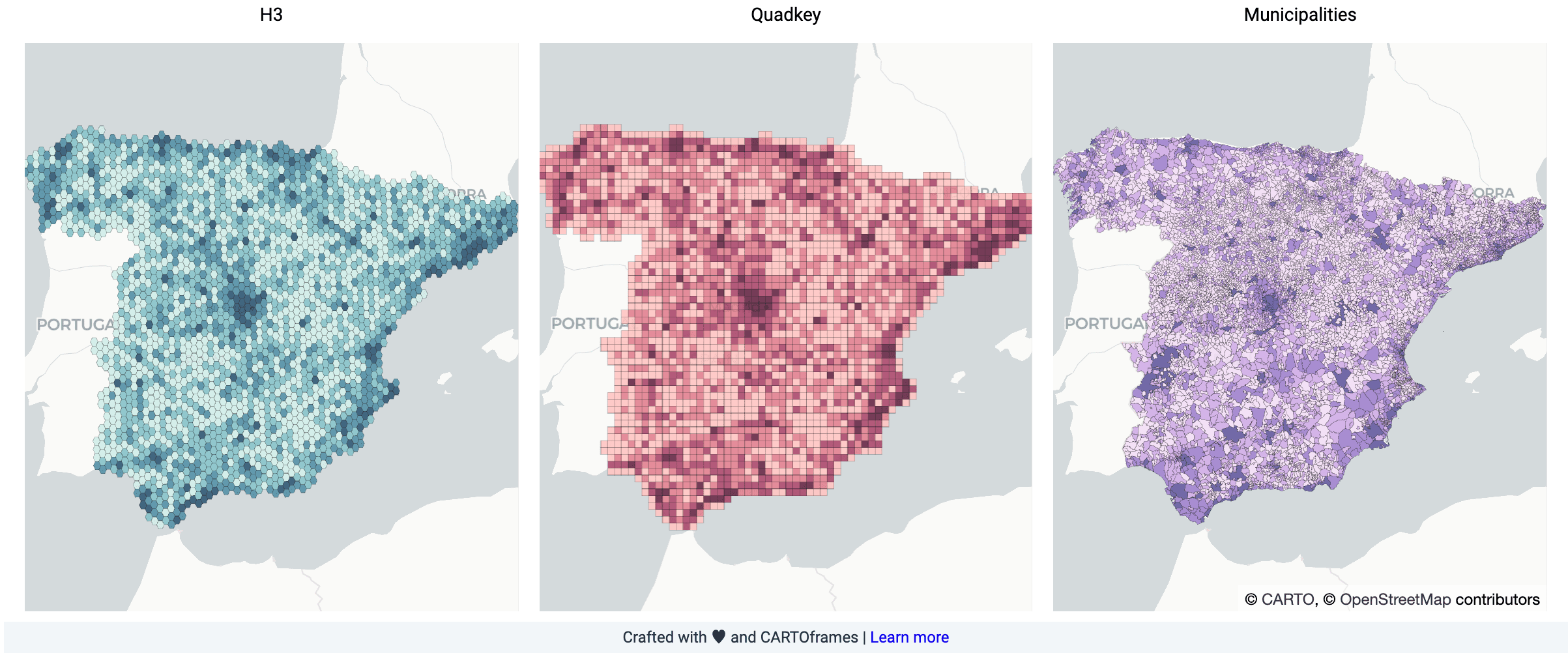
Wybór odpowiedniej siatki przestrzennej to jedna z ważniejszych decyzji metodologicznych w analizach logistycznych. CARTO przetestował w projekcie SEUR trzy podejścia: siatkę H3 (hierarchiczny system heksagonalny opracowany przez Uber), siatkę Quadkey (kafelkowanie bazujące na podziałach dwójkowych) oraz podział na gminy.
Siatka H3 na poziomie rozdzielczości 5 — z komórkami o powierzchni około 200 km² — zapewniała spójność geometryczną i łatwość agregacji danych z różnych źródeł. H3 jest szczególnie użyteczny, gdy dane z różnych systemów muszą być łączone: każda lokalizacja jest reprezentowana przez krótki, unikalny identyfikator, co czyni operacje łączenia (join) znacznie szybszymi niż klasyczne operacje na geometriach przestrzennych.
Podział na gminy, choć mniej regularny geometrycznie, miał kluczową zaletę operacyjną: SEUR prowadzi działalność według podziałów administracyjnych, ma dane zamówień zagregowane gminami i formułuje polityki biznesowe w oparciu o te jednostki. Na późniejszych etapach projektu, gdzie konieczne było uwzględnienie wymogów biznesowych, to właśnie gminy stały się podstawową jednostką analizy.
Po wyborze siatki przestrzennej kolejnym krokiem było zbudowanie prototypu narzędzia, które pozwalało dynamicznie symulować wpływ otwierania i zamykania centrów dystrybucji na metryki efektywności sieci.
Prototyp umożliwiał interaktywne dodawanie i usuwanie DC z mapy oraz natychmiastowe obliczanie skutków tych zmian dla dwóch kluczowych metryk: średniego dystansu od DC do klientów oraz rozkładu obciążenia między centrami. Do kosztów transportowych dodano również szacunkowe koszty operacyjne, by umożliwić analizę kompromisów (trade-offs) między kosztami transportu a kosztami utrzymania infrastruktury.
Konkretny przykład z projektu dobrze ilustruje wartość tego narzędzia. Analiza ujawniła jeden obszar z trzema DC zlokalizowanymi blisko siebie — żadne z nich nie znajdowało się przy strefie wysokiej gęstości zamówień zidentyfikowanej w kroku 1. Usunięcie środkowego DC (Puente Navalmoral) i przetestowanie wpływu tej zmiany pokazało, że dwa pozostałe centra mogły przejąć jego obsługę bez istotnego wzrostu średniego dystansu. Równocześnie zidentyfikowano obszar o wysokiej koncentracji zamówień, w którym brakowało DC — przetestowanie dodania nowego centrum w komórce o najwyższej gęstości popytu przyniosło poprawę metryki dystansu.
Wynik tych dwóch symetrycznych zmian — zamknięcia jednego DC i otwarcia drugiego w lepszej lokalizacji — to ta sama liczba centrów dystrybucji w sieci, ale z nieznacznie niższą średnią odległością na zamówienie. To dobry przykład tego, jak optymalizacja sieci nie zawsze oznacza inwestycję netto — czasem wystarczy przemieszczenie zasobów.
Ważna informacja metodologiczna: na tym etapie model przypisywał komórki siatki do najbliższego DC według odległości, bez uwzględniania pojemności centrów. Ograniczenia przepustowości zostały wprowadzone w następnym kroku.
Czwarty i kluczowy krok metodologiczny to zbudowanie formalnego modelu optymalizacji liniowej, który obliczył optymalne obszary dostaw dla każdego centrum dystrybucji. To tutaj pojawia się wynik, który stał się nagłówkiem tego artykułu.
Model pracował na poziomie gmin — ze względu na polityki biznesowe SEUR wymagające zgodności z podziałem administracyjnym. Funkcja celu modelu minimalizowała dwie zmienne jednocześnie.
Pierwszą zmienną była średnia odległość pokonywana przez pojazdy od DC do klientów. To bezpośredni koszt transportowy — paliwo, czas, zużycie floty.
Drugą zmienną było odchylenie od idealnego wyważenia obciążenia DC w szczycie sezonu. Model penalizował sytuacje, w których część centrów pracuje na 200% swojej pojemności, podczas gdy inne są w połowie puste. Nierównomierne obciążenie prowadzi do przeciążeń, opóźnień i pogorszonej obsługi klientów w najbardziej obłożonych centrach — nawet jeśli łączna pojemność sieci jest wystarczająca.
Do modelu bazowego dodano również dodatkowy koszt premiujący przypisywanie gmin do DC z tej samej prowincji — wymóg biznesowy SEUR wynikający z operacyjnych i administracyjnych realiów prowadzenia działalności w Hiszpanii.
Wynik optymalizacji był jednoznaczny: średnia odległość transportu zmniejszyła się z 18,99 km na zamówienie do 18,23 km na zamówienie. Różnica 0,76 km na zamówienie — czyli nieco ponad 4% — brzmi niepozornie. Ale przy 500 000 zamówień rocznie wyłącznie w segmencie cold chain, ta poprawa przekłada się na 380 000 mniej przejechanych kilometrów.
Żeby uzmysłowić sobie skalę: 380 000 km to niemal dziesięciokrotność obwodu Ziemi. To kilometry, które musiały być pokonywane, bo sieć nie była optymalnie zaprojektowana — nie dlatego, że kierowcy jechali złymi trasami, ale dlatego, że obszary dostaw były źle przypisane do centrów. Spatial Data Science pozwoliło to naprawić.
Jednym z ważniejszych wniosków metodologicznych z projektu SEUR jest wartość iteracyjnego podejścia do optymalizacji — stopniowego zwiększania złożoności modelu zamiast próby zbudowania od razu kompletnego rozwiązania.
Każdy z czterech kroków opisanych powyżej dostarczał wartościowych wyników biznesowych niezależnie od kolejnych. Analiza klastrów DBSCAN sama w sobie dała SEUR obraz przestrzennych wzorców popytu, którego wcześniej nie mieli w takiej szczegółowości. Narzędzie do symulacji otwarcia i zamknięcia DC umożliwiło testowanie scenariuszy przed podjęciem kosztownych decyzji inwestycyjnych. Dopiero na końcu pojawił się model optymalizacji liniowej z pełną formalizacją matematyczną.
To podejście — zapewnienie wartości biznesowej na każdym kroku, z rosnącą złożonością — jest znacznie bezpieczniejsze projektowo niż próba zbudowania od razu kompletnego „czarnego pudełka". CARTO wprost podkreśla tę filozofię: iteracyjne stosowanie różnych technik Spatial Data Science, dodając złożoność stopniowo, pozwoliło dostarczać sensowne wyniki i wnioski na każdym etapie.
Projekt opisany w tym artykule był pierwszym etapem dłuższej współpracy. CARTO i SEUR zidentyfikowali kilka obszarów, które wymagają dalszego rozwinięcia, by model był jeszcze dokładniejszy i bardziej użyteczny operacyjnie.
Wzbogacenie danych o dostępność gruntów przemysłowych to naturalny następny krok w identyfikacji potencjalnych lokalizacji dla nowych DC. Dane o terenach przemysłowych, dostępności infrastruktury i kosztach gruntów — zintegrowane z mapą gęstości popytu — pozwalają wskazać nie tylko gdzie nowe centrum powinno być zlokalizowane z logistycznego punktu widzenia, ale też gdzie jest realistycznie wykonalne.
Zastąpienie odległości euklidesowych odległościami sieciowymi — przeliczanymi po rzeczywistej sieci drogowej — to kolejny kierunek poprawy dokładności. Model w pierwszym etapie używał odległości geograficznej jako przybliżenia. Rzeczywiste trasy drogowe mogą się od niej znacznie różnić, szczególnie w obszarach górskich lub przy naturalnych przeszkodach.
Włączenie do modelu wielowarstwowej struktury sieci to najtrudniejsze metodologicznie rozszerzenie. Sieć logistyczna SEUR nie jest dwustopniowa (DC → klient), ale wielostopniowa: obejmuje magazyny centralne, platformy tranzytowe, lokalne centra dystrybucji i punkty dostawy do klienta. Pełny model musi opisywać relacje między wszystkimi tymi elementami.
Polska zajmuje unikalne miejsce w europejskiej logistyce. Jest centrum logistycznym dla Europy Środkowej i Wschodniej, z rosnącą siecią centrów fulfillmentu i magazynów. Polscy operatorzy — zarówno globalne firmy działające w Polsce, jak DHL czy DPD, jak i krajowi gracze — stają przed podobnymi wyzwaniami co SEUR: sieciami zbudowanymi historycznie, które nie zawsze odpowiadają aktualnemu rozkładowi popytu.
Metodologia zastosowana przez CARTO w projekcie SEUR jest w pełni transferowalna na polski rynek. Dane potrzebne do analizy — historyczne zamówienia z geolokalizacją, lokalizacje i pojemności centrów dystrybucji, obecne obszary dostaw — każdy operator logistyczny posiada. Brakuje narzędzi i kompetencji, by te dane przekształcić w wiedzę o strukturze sieci i model optymalizacyjny.
Dla firmy obsługującej 500 000 zamówień rocznie w Polsce, poprawa średniej odległości transportu o 4% może oznaczać oszczędność rzędu kilku milionów złotych rocznie — w zależności od kosztów paliwowych, struktury floty i taryf. Przy obecnych cenach paliwa i rosnących kosztach pracy kierowców ta liczba jest nie do zignorowania.
OPGK Rzeszów jako wyłączny partner CARTO w Polsce oferuje dostęp do tych samych narzędzi i metodologii, które stały za sukcesem SEUR — zaadaptowanych do polskich realiów rynkowych, polskiej struktury drogowej i polskich wymogów prawnych dotyczących danych.
Liczba 380 000 km rocznie nie wzięła się z przybliżeń ani z optymistycznych założeń. To matematyczny wynik dobrze zdefiniowanego modelu optymalizacyjnego, zasilanego rzeczywistymi danymi operacyjnymi SEUR i weryfikowanego w każdym kroku metodologicznym.
Za tym wynikiem stoi konkretna metodologia: analiza klastrów DBSCAN do diagnozy rozkładu popytu, dyskretyzacja przestrzenna z użyciem H3 i siatki gminnej, iteracyjna symulacja zmian w sieci, i wreszcie model optymalizacji liniowej minimalizujący jednocześnie dystans transportowy i nierównowagę obciążenia centrów dystrybucji.
Kluczowy wniosek wykracza poza liczby. Spatial Data Science w logistyce to nie estetyczna warstwa mapowa nakładana na raporty operacyjne. To narzędzie obliczeniowe, które przekształca dane o lokalizacji — zamówień, centrów dystrybucji, obszarów dostaw — w model matematyczny pozwalający odpowiedzieć na pytanie, które każdy operator logistyczny powinien sobie zadawać regularnie: czy nasza sieć jest zaprojektowana optymalnie względem rzeczywistego rozkładu popytu?
W przypadku SEUR odpowiedź na to pytanie była warta 380 000 km rocznie. W przypadku polskich operatorów logistycznych podobna odpowiedź czeka na odkrycie.
Źródła: CARTO Customer Story — SEUR Supply Chain Network Optimization (carto.com/customer-stories/seur-supply-chain-management) oraz CARTO Blog — Supply Chain Network Optimization: SEUR Case Study (carto.com/blog/supply-chain-network-optimization). Autorem technicznej analizy po stronie CARTO był Miguel Álvarez, Lead Data Scientist w CARTO.
OPGK RZESZÓW S.A.
Geodetów 1
Rzeszów 35-328
Polska
